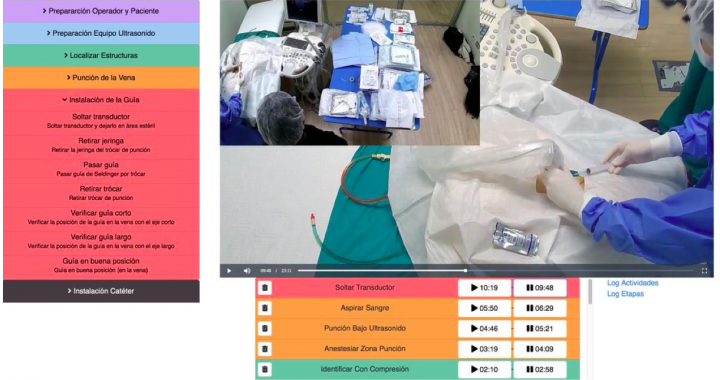
Benjamín Ayancán Guerrero, Denis Parra Santander.
JI3 2020, número 11, páginas 116-126.

Resumen
En las revisiones sistemáticas de literatura médica, el creciente número de estudios publicados implica un trabajo de selección para los revisores, quienes pueden llegar a examinar miles de artículos depositados en bases de datos y sistemas de indexación. Trabajos anteriores han modificado la codificación de textos para mejorar su representación, sin embargo, estos enfoques no ahondan en la desproporcionalidad de clases en data sets con deficiencias de construcción. En este contexto, Active Learning (AL) permite seleccionar aquellos datos más relevantes para etiquetar, reduciendo tanto la cantidad requerida como el costo asociado. En este trabajo, evaluamos la incidencia de modelos de lenguaje neuronal BERT y Word2Vec, además del entrenamiento con AL y Data Augmentation (DA) para manejar la asimetría en los data sets incluidos en el desafío CLEF eHealth 2017.
Leer más…